

아래는 지난겨울에 했었던 작업이다. 비정형 텍스트 자료(소설, 시나리오, 댓글 등)에서 일정한 정보를 추출하고 패턴을 발견하는 작업을 때때로 해왔다. 최근에 실제 대규모 행정 데이터를 활용하여 이와 같은 문제를 다룰 기회를 얻게 되었다. 전산망에서 구조화가 되어 있는 자료라 문학 작품보다는 다루기 쉬울(?) 것으로 보인다.
소설이나 시나리오의 서사를 어떻게 데이터화하여 다룰까?
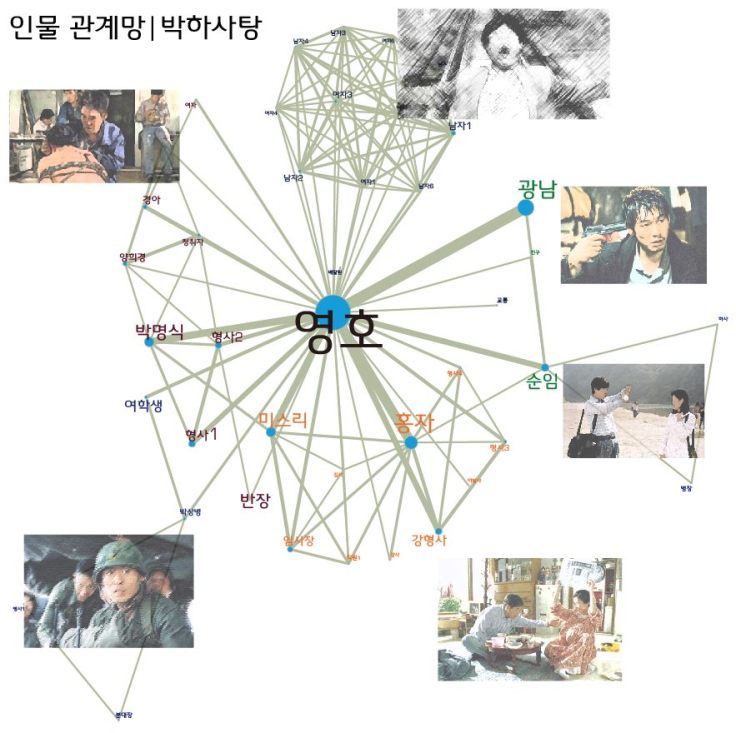
관건은 특별한 가공이 되어 있지 않은 문건에서 체계적인 정보를 자동화된 방식으로 추출하는 것이다. 우선 내가 좋아하는 이창동 감독의 박하사탕 시나리오를 가지고 연습을 해봤다.
영화의 각 씬에 함께 등장하는 수준에 따라 관계망을 그리고, 인물별로 영화의 각 씬에 등장하는 횟수를 측정했다. 그림에서 선이 굵을수록 함께 등장하는 장면이 많음을 뜻하고, 인물을 뜻하는 점의 크기는 등장 씬의 수이다. 하위 네트워크 구조를 이해하기 쉽게 영화의 몇 장면을 함께 담았다. 주요 시점에 따라서 등장인물 이름 색을 달리했다.
주인공(영호)의 영원한 사랑이자 닿을 수 없는 이상향을 상징하는 순임, 현실의 한계이자 동시에 현실의 냉혹함을 드러내는 홍자, 주인공의 공허한 욕망의 끝을 상징하는 미스리, 역사의 굴곡 가운데 주인공의 인간적 파멸과 관련된 여학생, 박명식 등이 각자의 네트워크를 구성하고 있음을 알 수 있다. 그리고 순임과의 마지막 만남의 문을 열어주는 대사는 적어도 큰 비중을 차지하는 광남 또한 눈에 띈다.

댓글 남기기